由于产品业务的迭代升级,我们需要对现有的日志转储以及分析系统进行升级,在准备升级的开始阶段,我们查阅了大量的资料来进行技术选型,最终看到了由 Cloudflare 提供的一篇文章,描述了他们在升级该系列产品的过程《使用ClickHouse 来处理超过600万每秒的 HTTP 请求分析》,最终我们选择了与之类似的架构。即使用 Kafka 做消息流转,使用 ClickHouse 进行数据库存储与分析。
在使用 ClickHouse 之前我们还尝试过使用ELKF(ElasticSearch、LogStash、Kibana、FileBeat)来进行分析处理,但不幸的是 ELKF 无法支撑我们目前的数据量。ELFK 在处理超过 10k QPS的时候,就已经陷入瓶颈了,无论是写入数据还是查询数据方面,也许是因为我们硬件配置不足吧?,测试平台配置如下
| Operating System | CentOS 7.9 with Docker |
| CPU | Dual E5-2650 (2x 8核 16线程 2.00GHz) |
| Memory | 64 Gib |
| Storage | 2x 500Gb SATA SSD / Raid0 |
| Network | 1 Gbit LAN |
在实际测试过程中,发现 LogStash 和 ElasticSearch 在处理 10k QPS 数据时,CPU被完全榨干了。几番调试后,发现并无优化空间,于是转战 ClickHouse,在几经波折后,也是成功上线了产品的 Alpha版本。

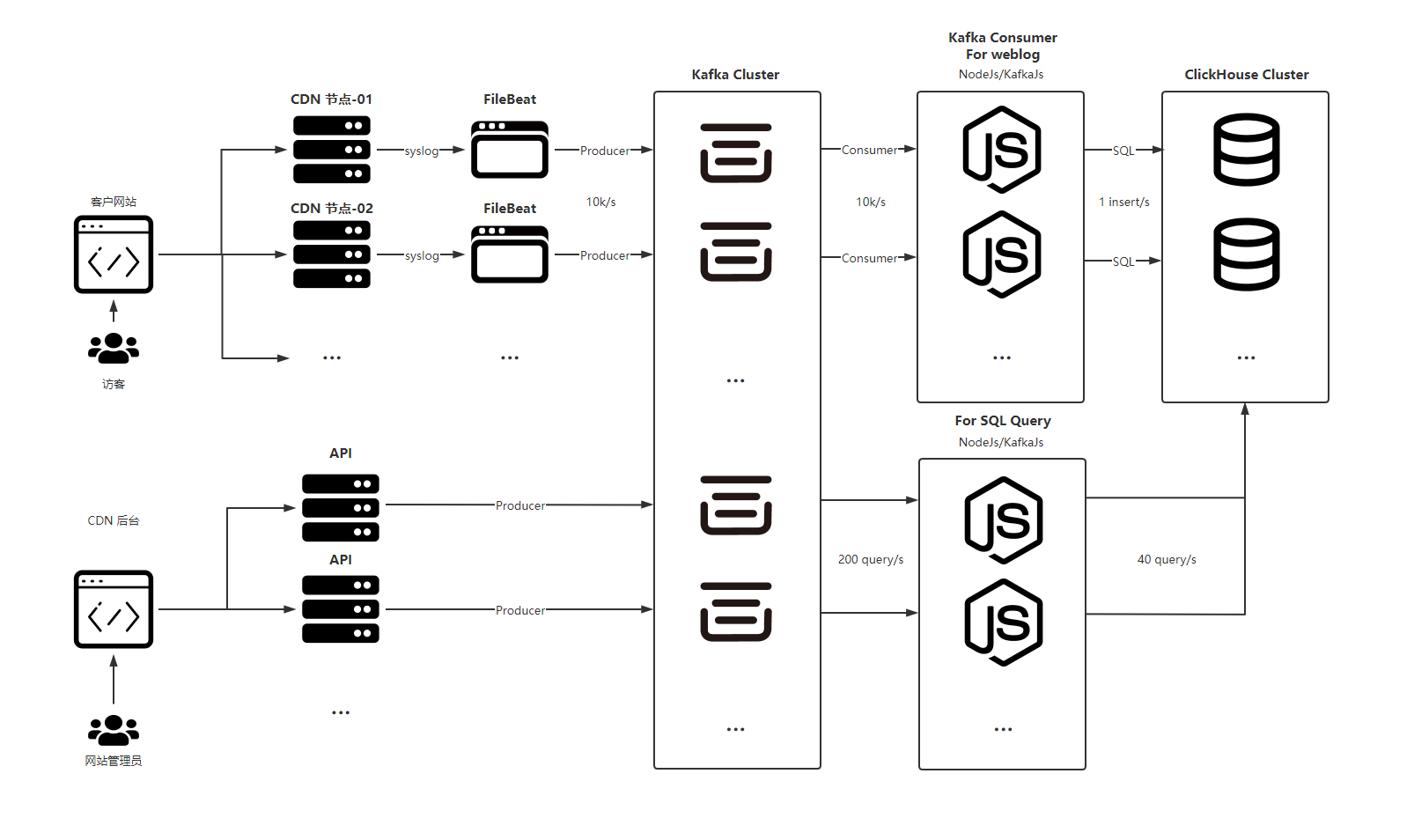
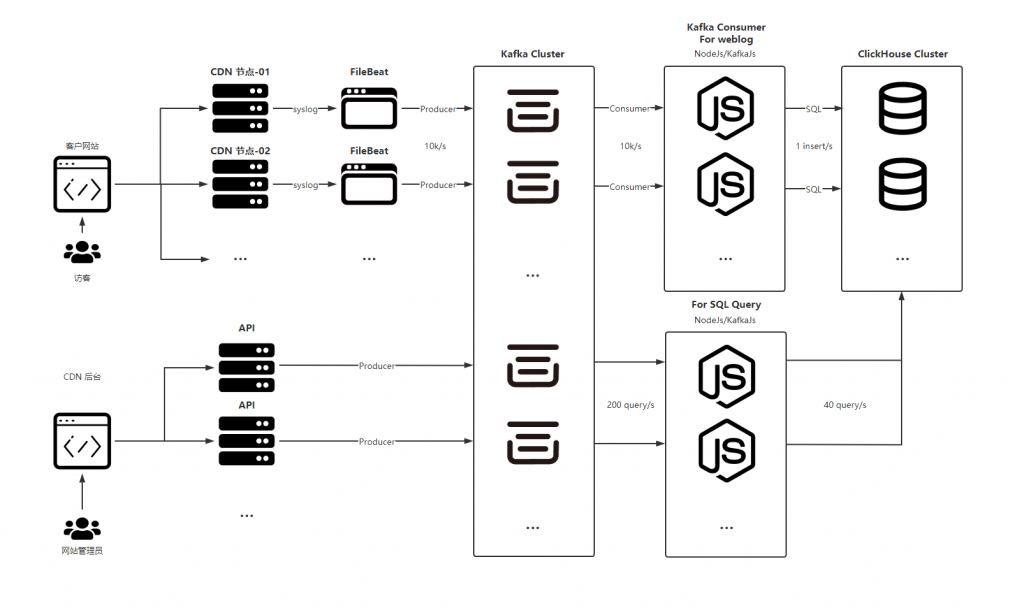
在 FunCDN 的 海克斯矩阵 产品中,我们的业务流程如下
- 使用 FileBeat 来收集 Nginx 所产生的日志
- 通过 Kafka 将日志信息流转
- 使用 KafkaJS (NodeJs)消费日志,按每秒写入1次的频次写入 ClickHouse *
- ClickHouse 中使用了大量的聚合表来减少对硬盘的检索次数和IO占用
- 将用户请求也通过 Kafka 进行流转,用于削峰以及使用异步来提升 API 性能 *
在以上环节中,有 2 项标记*的流程,对于这么处理的原因如下
3. ClickHouse 官方文档 – 性能 中有介绍,建议每次插入至少 1000 行 或 每秒不超过 1 个写入请求,这是因为 ClickHouse 在每次插入数据时,会生成对应的一个按主键排序好的文件分片,太多的文件分片会导致磁盘IO过高,严重影响性能。
5. 由于 ClickHouse 的工作模式是对磁盘文件进行逐行扫描,所以不宜进行高并发查询,我们在此对SQL请求进行了队列处理,执行不超过 40个 并发请求(参考于 CloudFlare)。
最终,生产环境中,目前每日新增大约 5 – 7 亿条记录,平均 QPS 在 10k 左右,突发 QPS 最高 80k。集群整体使用负载平均在 30% ,突发至 70 %,把 ELKF 按在地上来回摩擦。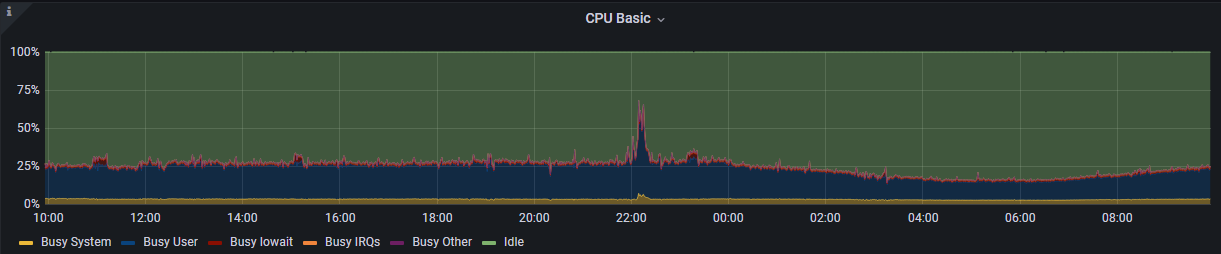
关于查询性能
在 ELKF 中,聚合查询请求在按日进行分片的结构下,对单日数据进行聚合查询时,请求返回耗时至少需要5秒,当时测试的数据已经删除,无法找到相应的图片。
在 ClickHouse 中,我们按 指标类型、时间维度、聚合类型 建立了 约 60 张聚合表来进行预聚合处理,这么做的好处就是,在实际的业务处理中无需对 底表 进行大量扫描用来查询,典型的空间换速度。
聚合表建立大致如下
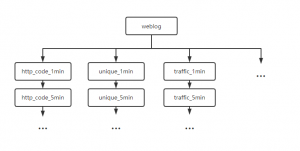
新的消息流转如下
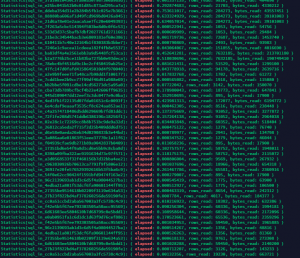
最终实现业务查询(聚合表)时间均小于 1s
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏