7 月 5 日消息,在今晚的理想智能驾驶夏季发布会期间,理想汽车宣布,端到端 + 视觉语言模型早鸟计划正式启动,号称可让车更智能、更像人。

汇总主要信息如下:
理想汽车称端到端模型的优势在于“高效传递”和“高效计算”两方面:端到端是一体化的模型,信息都在模型内部传递,具有更高上限,用户所能感受到的整套系统的动作、决策都“更加拟人”;一体化模型可在 GPU 里一次完成推理,且端到端延迟更低,用户可感知到“眼”“手”协调一致,车辆动作响应及时。
一体化模型可实现端到端的可训,完全数据驱动。官方表示,对于用户来说最大的感受就是 OTA 的速度越来越快。

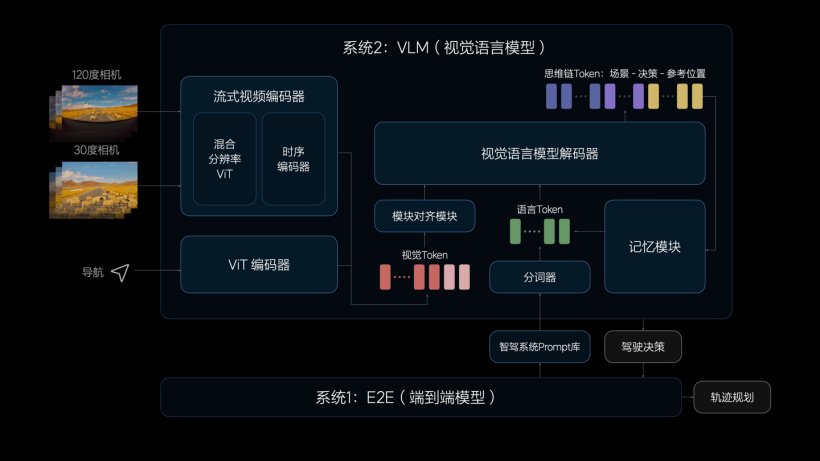
视觉语言模型方面,其整体算法架构由统一的 Transformer 模型组成,将 Prompt(提示词)文本进行 Tokenizer(分词器)编码,然后将前视 120 度和 30 度相机的图像以及导航地图信息进行视觉信息编码,通过图文对齐模块进行模态对齐,统一交给 VLM 模型进行自回归推理;VLM 输出的信息包括对环境的理解、驾驶决策和驾驶轨迹,并传递给系统 1 控制车辆。
官方表示,该系统整体设计存在三个亮点:设计了流式视频编码器,能缓存更长时序视觉信息;增加了记忆模块,缓存了多帧历史信息,可解决超长上下文推理时延问题;设计了智能驾驶 Prompt 问题库,系统 2 可以“思考”当前驾驶环境并给系统 1 合理驾驶建议,系统 1 也可在不同场景下调用不同 Prompt 问题,主动向系统 2 进行“求助”。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






