英特尔今天正式推出了基于 Meteor Lake 架构的第一代英特尔酷睿 Ultra 处理器,首批上市的处理器涵盖酷睿 Ultra 7/5 系列,这次 Meteor Lake 架构通过 Foveros 3D 封装技术将全新的 SoC 模块、Intel 4 计算模块、全新的 GPU 单元和 IO 模块封装在一起,能耗相比此前有重大进步。
多级 XPU 设计带来高达 34TOPS 的 AI 算力,为 AI PC 全面爆发打下基础。

酷睿 Ultra 处理器平台的集合了英特尔八大先进技术。
一是 3D 高性能混合架构,和 3D Foveros 封装技术;二是采用了 Intel 4 制程工艺的计算模块,多达 6 个性能核,8 个能效核,以及 2 个低功耗岛能效核,一共加起来会支持 22 个线程;三是主频高达 5.1GHz;四是集成了英特尔 Arc GPU 显卡,配备多达 8 个 Xe 核显;五是支持多路 AI 加速处理的 NPU;六是支持最多 64GB 的 LPDDR5/5X-7467 和 96GB DDR5-5600 内存;七是支持雷电 4 外设接口;八是集成了英特尔 Wi-Fi 6E 的无线网卡。
接下来,我们具体看下英特尔酷睿 Ultra 架构的诸多新特性。

架构特性
Meteor Lake 是英特尔第一个采用 Intel 4 制程工艺的处理器产品,Intel 4 在英特尔“四年五节点”制程发展计划当中是最重要的一环,Intel 4 的量产标志着英特尔非常顺利的进入 EUV 时代,同时 Intel 4 的量产也为 Intel 3 和后续的 Intel 20A、Intel 18A 的开发打下了基础。
Intel 4 对比 Intel 7 实现了 2 倍晶体管密度的提升,同时这一代制造工艺也是优化了 CPU 高性能逻辑库,进一步实现了更高密度的金属层,达到了更高效的供电。从工艺角度来看,相比于 Intel 7,Intel 4 实现了 20% 的能效提升。这里有关 Meteor Lake 架构相关解析,可以参考之前内容,这里就不过多赘述。

Meteor Lake 重要的一个设计目标就是要提升处理器的能效。新的 P-Core 和 E-Core 微架构提升了每瓦的性能执行效率,同时通过分离式模块化设计,酷睿 Ultra 处理器的 SoC 模块引入了低功耗岛 LPE-Core,同时把内存控制器、视频编解码器、显示处理单元、NPU 等都集成在低功耗岛,实现了低功耗运行处理单元。

模块化设计还实现了模块的单独供电控制,更有效提升了整个处理器的能耗管理。在硬件之上,配合操作系统,硬件线程调度器实现了更高级的 3 阶线程调度管理,有效的帮助操作系统去实现逻辑处理器核的线程安排和执行。从 Raptor Lake 到现在的 Meteor Lake,英特尔硬件线程调度器每一代都针对处理器的特性进行优化,这些都保证了 Meteor Lake 能够实现更高速以及更节能的计算和运行。
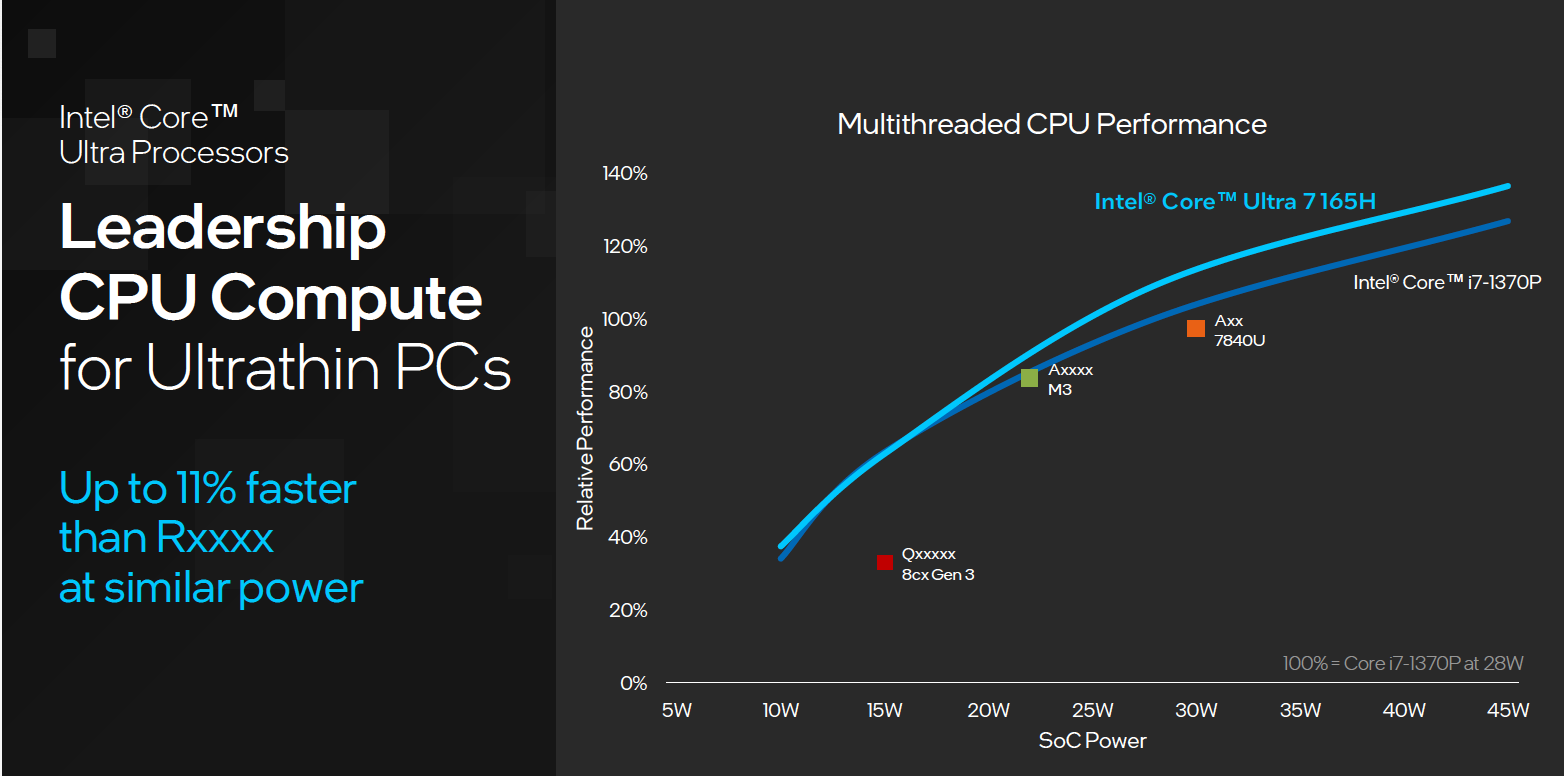
英特尔酷睿 Ultra 处理器在 SPEC 2017 相关测试中我们看到,酷睿 Ultra 7 165H 相比前一代的 i7-1370P,在 28W 功耗情况下,酷睿 Ultra 有相当不错的表现。相较于竞品,酷睿 Ultra 更多的功耗可以有更高的性能表现。整个 CPU,尤其是在轻薄 PC 当中,在一个类似的功耗区间上,相较于竞品有 11% 的多线程性能领先。
功耗的部分,酷睿 Ultra 7 165H 在运行 Netflix 视频录像功耗测试中,我们可以看到,整个功耗来看大概是 1150mW 左右。由于酷睿 Ultra 处理器的低功耗岛的加入,相比于上一代酷睿 i7-1370P 可以节省 25% 的功耗。

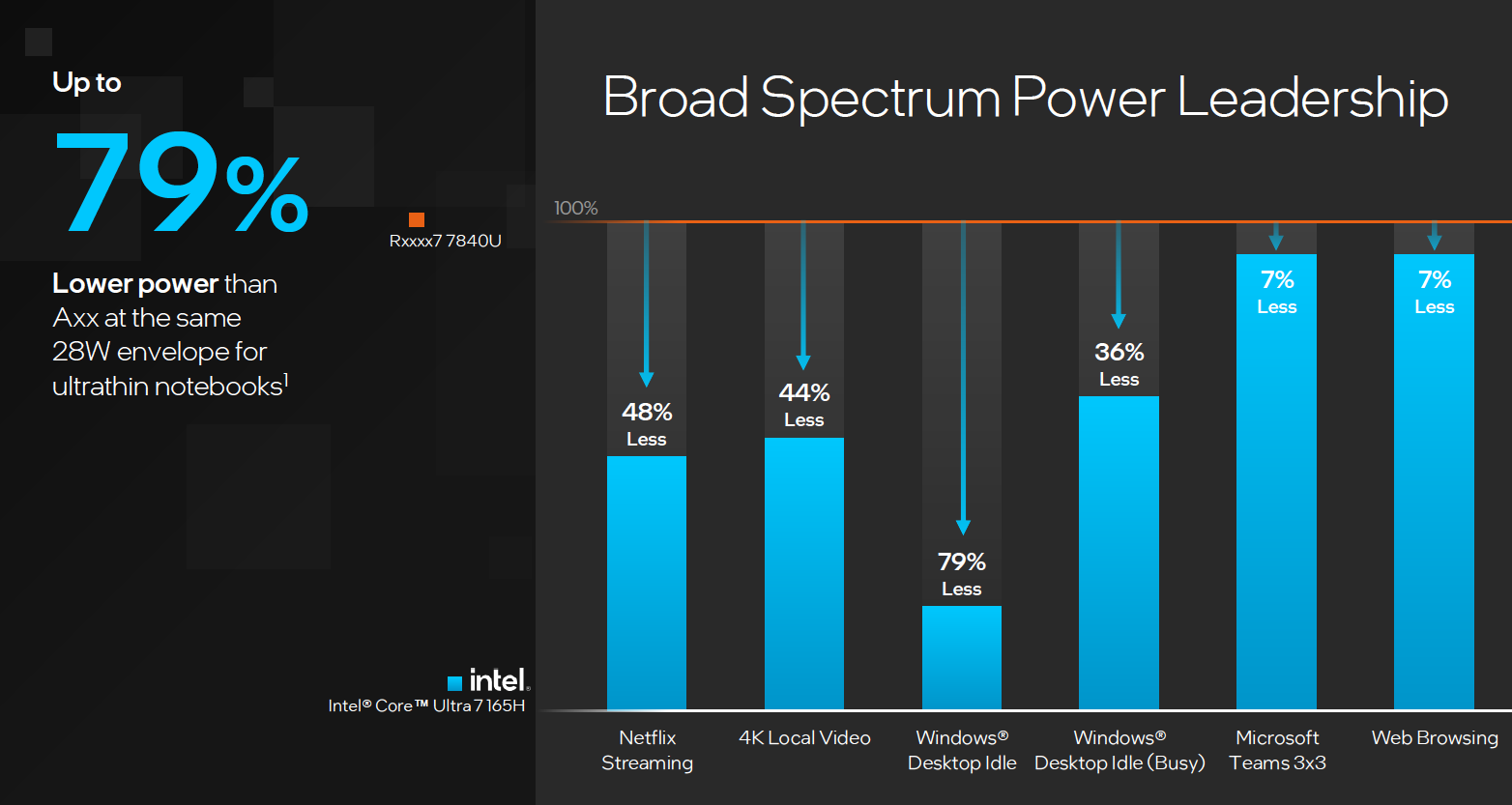
其他场景下,酷睿 Ultra 7 165H 相比竞品更省电,比如说 Windows 空闲待机状态相比于繁忙状态下有非常明显的功耗节省,最多功耗节约可达 79%,像在 Netflix 直播或者是 4K 本地视频播放,也有 40% 以上的功耗节省。一般日常的使用情境,微软的 Teams 或者是网页浏览,也有 7% 左右的功耗节省。
计算单元
回到酷睿 Ultra 的计算模块,最主要的两个核心是 P-Core 和 E-Core。这边的 E-Core 微架构从前一代的 Cracemont 升级到了 Crestmont。架构上的提升在保证最低功耗的条件下,进一步提高了 E-Core 的吞吐能力,并且增强了 AI 计算能力,这样的话,E-Core 的 VNNI 指令集的执行也得到了很大提升。
P-Core 微架构从前一代的 Golden Cove 升级成了 Redwood Cove,在进一步提升性能的前提下,很大程度上提升了能效,P-Core 和 E-Core 加起来,不管是做极轻薄的笔记本还是高性能笔记本,都可以使产品设计变成其最佳状态。LPE-Core 低功耗岛位于 SoC 模块,架构和 E-Core 架构是一样的,都是基于 Crestmont 架构,所以 LPE-Core 在更低能耗下可以提供完整的计算能力。

E-Core 的微架构演进,继续提高 IPC 能力,让它的计算能力变得更高。另外,不管是 E-Core 还是 P-Core,英特尔都提高了峰值预测能力,让它的指令执行变得更有效率。E-Core、P-Core 以及 LPE-Core,都是统一通过英特尔线程调度器做调配。
E-Core 上进一步提升了 VNNI 指令执行能力,为 AI 加速做准备。不管是 E-Core 还是 P-Core,都是支持同一个指令集,任务能够在 P-Core 上执行,就可以在 E-Core 上执行甚至是 LPE-Core 上执行。不管是整数运算、浮点运算,包括 AI 的各种各样任务都是可以的。这样的话,不管任何的计算任务,包括 AI 运行,可以由英特尔线程调度器做控制和动态分配,可以在 E-Core、P-Core 和 LPE-Core 上做实时转换,需要性能需要响应速度的时候往 P-Core 上移,需要降低功耗的时候,就往 E-Core 甚至是 LPE-Core 上移,因此,指令在所有的 Core 上都可以得到顺利执行。

P-Core 是传统的大核,在不断提升性能、吞吐能力、内部总线、外部总线、带宽,包括所有的缓存的同时,英特尔在 Meteor Lake 上进一步优化了性能效率,降低 P-Core 的执行功耗。Meteor Lake 在能耗控制上相比前一代有很大优势。整个 P-Core、E-Core、LPE-Core,都是在英特尔线程调度器下做动态、实时的分布。英特尔线程调度器到现在已经演进到了第三代,它与操作系统高度结合,外部软件适配已经做得完善,所以 Meteor Lake 也已经可以提供更好的能效和功耗上的表现。

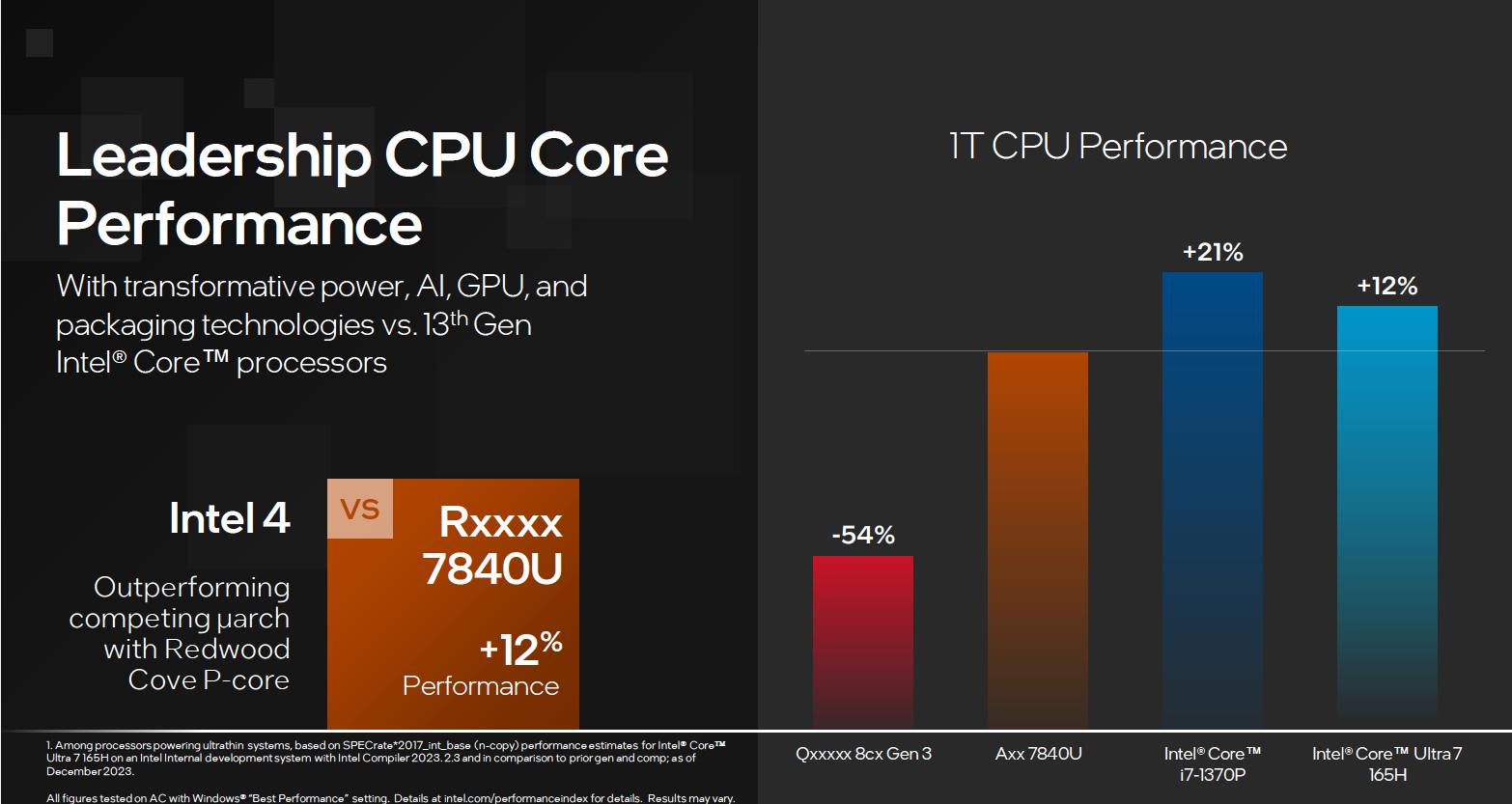
英特尔酷睿 Ultra 处理器在多线程的表现得到大幅的提升,相较于酷睿 i7-1370P 来看,酷睿 Ultra 7 165H 有 8% 的性能提升。相较于竞品来说,有 11% 的性能领先。

单线程部分。,相较竞品,酷睿 Ultra 有不错的性能领先的优势,相比竞品大概有 12% 的性能领先。当然,在英特尔 13 代酷睿处理器上主频会稍微高一些,酷睿 Ultra 与之相比稍微有一点距离,但是和竞品相比还是有非常好的领先优势存在。
在硬件配置接近的情况下,英特尔酷睿 Ultra 7 155H 在 UL Procyon 视频剪辑、PugetBench for Premiere Pro 以及 PugetBench for Lightroom 中表现相比于上代 i7-1360P 和竞品有一个明显的领先优势,在视频编辑中有 31% 的性能领先,在 Premiere Pro 中有 41% 的性能领先,Lightroom 中有 19% 的性能领先。

GPU 单元
再看一下 GPU 部分,这一代英特尔酷睿 Ultra 集成了英特尔 Arc GPU,与 13 代不同,这一代采用全新的 Xe LPG 架构,并支持 DX12 Ultimate 特性,也就是说,集显也是支持硬件光线追踪和网格着色这些新的图形特性。
在编解码能力上,Arc GPU 除了常见的 H.265、H.264 外,还支持 AV1 编帽,最高可以支持 8K 10bit HDR。显示引擎部分,这一代集显同时支持 4 路显示通道,从显示接口规范来看,HDMI2.1、DP 2.1 目前酷睿 Ultra 都支持,这两项规范最高带宽达到 20Gbps,另外还支持 eDP 1.4b。
另外两个高级特性就是 DP4A 引擎和 XeSS,DP4A AI 指令的支持可以做到更快加速 AI 计算。XeSS 超级采样通过 AI 实现对游戏流畅度和清晰度的提升。

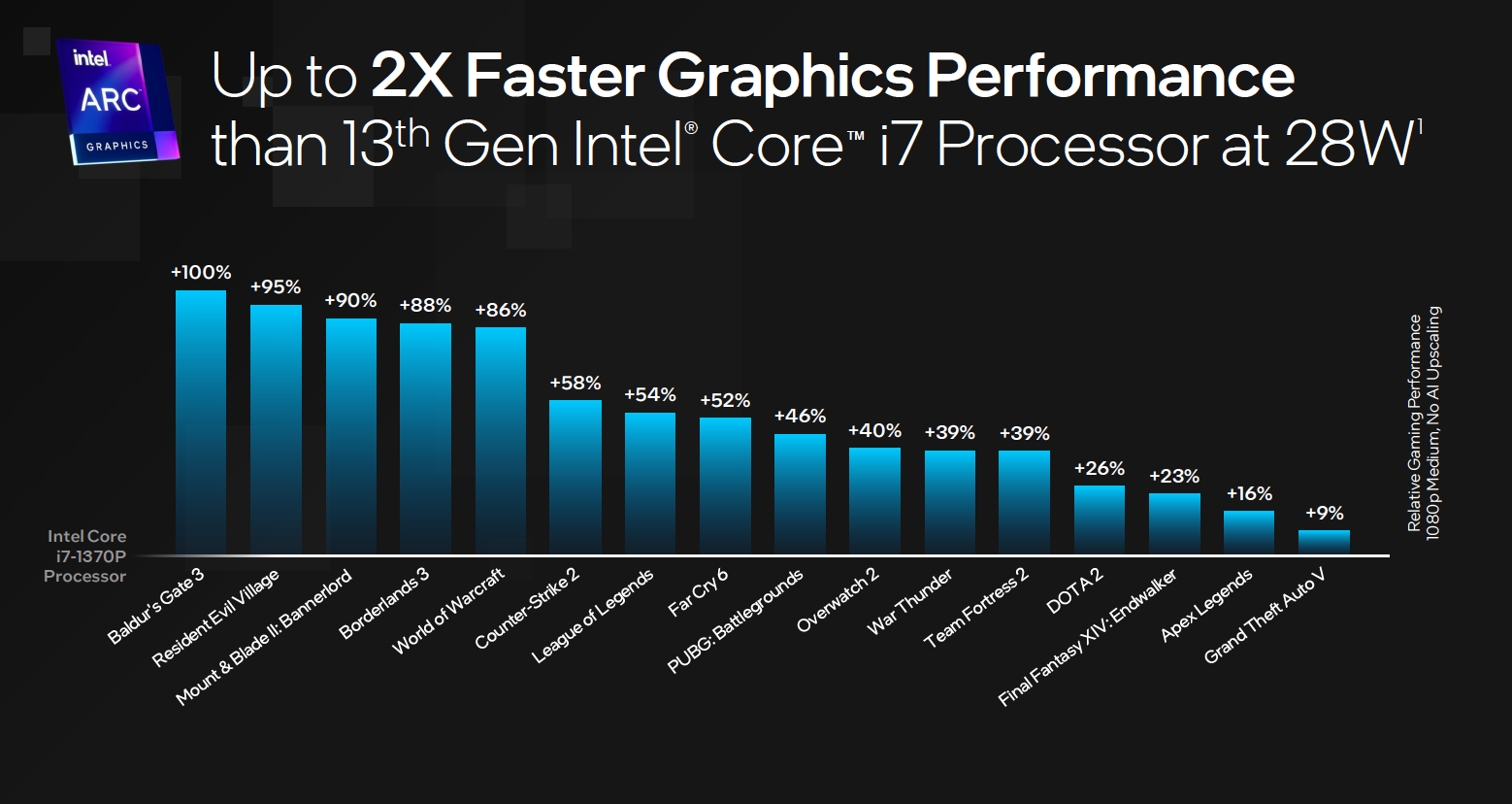
具体来看,酷睿 Ultra 在《博德之门 3》这个游戏上面,相比上一代 i7-1370P 的集显有 100% 的提高。在其他主流游戏上,如《生化危机》《孤岛惊魂》《守望先锋》等,FPS 相比前一代都有大幅度改善。这些游戏主要是在超薄笔记本电脑上,几款市面上主流的游戏,所有测试均在 1080P 中画质下进行。
在于另外几款 PC 产品的对比中,我们看到酷睿 Ultra 7 165H 平均相比于竞品有 5% 的领先优势。

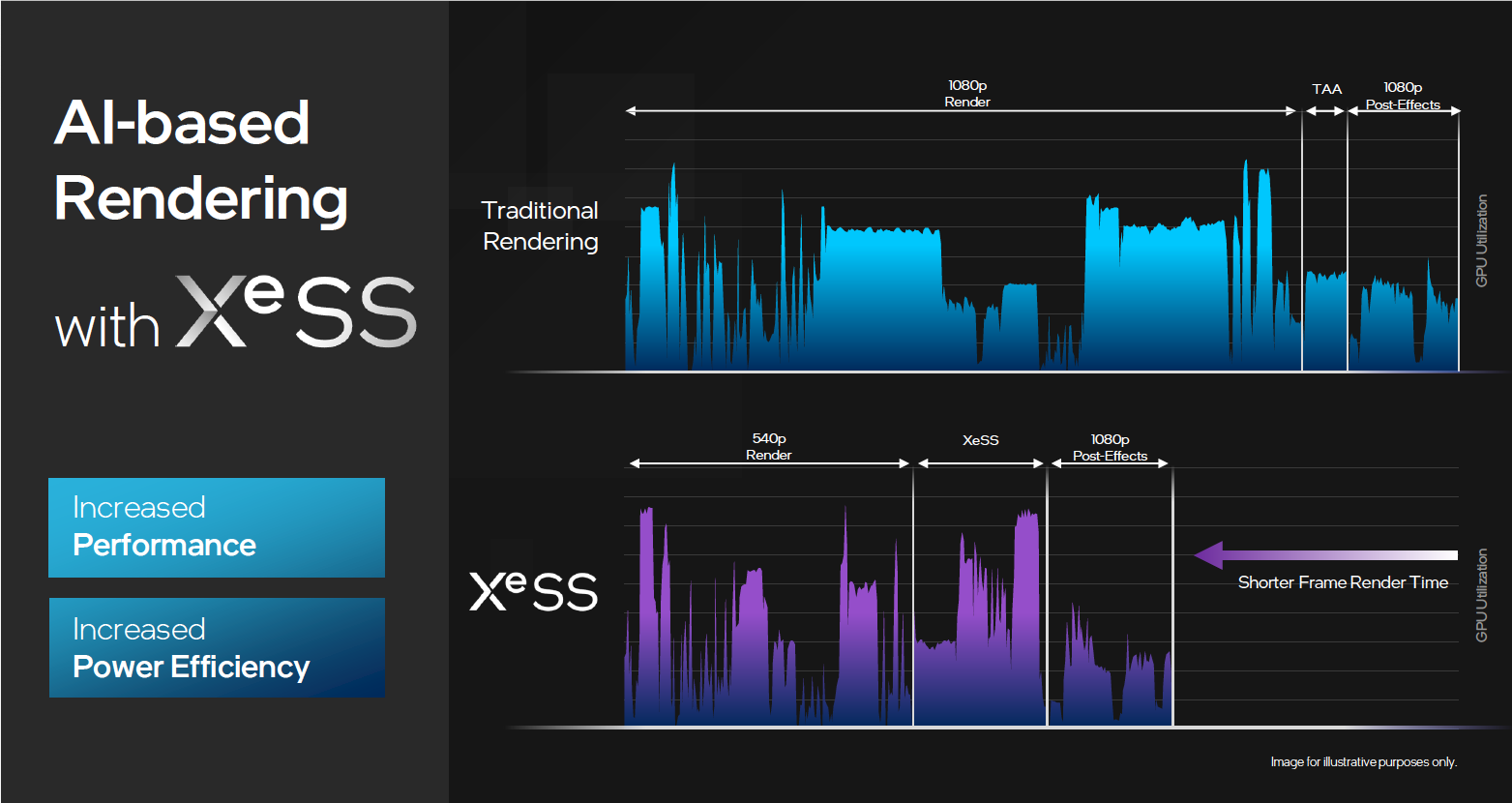
这一次基于 AI 的 XeSS 超级采样技术也为游戏带来了画纸上的提升,我们知道,在玩游戏的时候,如果要提升画质,必定会牺牲帧率,流畅度会大打折扣。XeSS 在不改变硬件配置的情况下,通过自身 AI 指令,首先把每一帧的分辨率降级,比如从 1080P 变成 540P 的渲染,这样可以保证更高的帧率流畅度,然后先把低像素的每一帧都渲染完,接下来通过 XeSS 技术升级到更高的像素分辨率。这样,在保证同样的帧率的情况下,分辨率提升到了更高的级别。等于既保证了帧率的流畅,又保证了画面像素质量,因为把原本用户要求的目标像素先做一个降级,降级之后可以保证依然是很高的帧率,再通过 XeSS 技术,把像素的质量再升级回来,这样在保证帧率的前提下也保证了游戏画面质量。
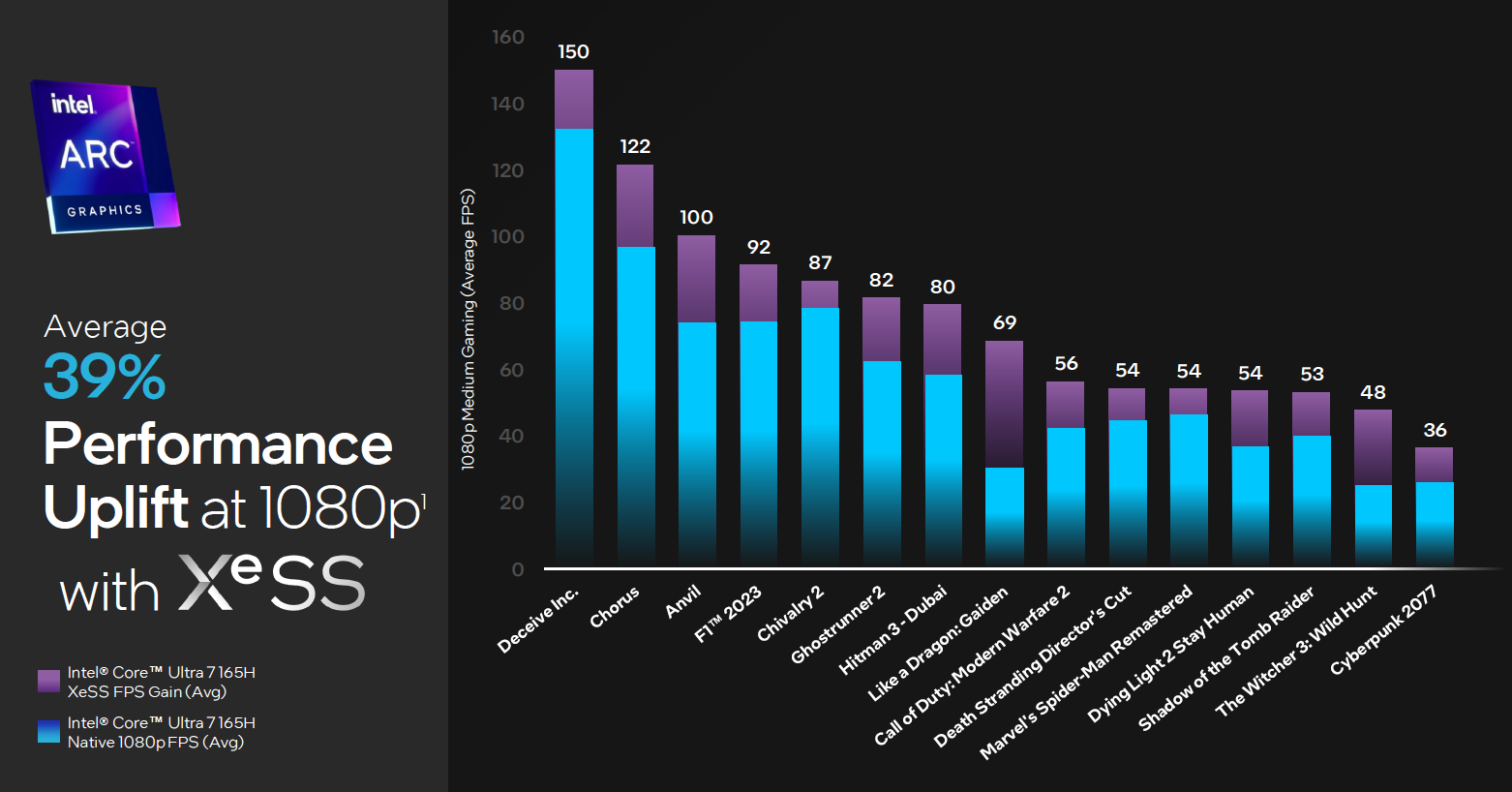
打开 XeSS 之后,在不同的游戏上,增加的幅度会有不同,一些比较受欢迎的游戏,像《杀手》《如龙 7 外传》《使命召唤》《古墓丽影》《赛博朋克》等游戏借助 XeSS 帧率都有明显的提升。
在《幽灵行者 2》游戏上,结合酷睿 Ultra 和 Arc 显卡,在 1080P 画质下配合 XeSS 技术,同样的分辨率相比前一代酷睿处理器有 3 倍的帧率提升,并且在同样的帧率下,也会更加省电。

AI 处理能力
AI 无疑是今年最为火热的话题,英特尔酷睿 Ultra 处理器可以说是为 AI PC 场景应运而生的新一代平台。酷睿 Ultra 有三个 XPU——CPU、GPU、NPU,它们都可以来做 AI 处理。目前酷睿 Ultra 总体算力现在可以达到 34TOPS。英特尔推荐用户去选择不同架构来处理 AI 工作负载,这次酷睿 Ultra 引入了全新的 NPU,这个 NPU 的特点是在处理 AI 工作负载时非常高效也非常省电,因为它是专门为 AI 工作负载来设计的一款处理器。

在开视频会议或者是在观看流媒体的时候,因为开会时间都比较长,观看时间也比较久,这时候效率提升往往可以实现比较明显的电池节省,所以 NPU 比较适合长时间的使用。再比如 CPU,CPU 也有专门的 AI 加速指令集,比如说 VNNI,可以专门用来加速 AI 工作负载处理。CPU 更推荐在运行对延时比较敏感的这类应用场景下使用,比如说语音控制、语音识别,相对其他的 NPU、GPU 来讲,CPU 启动起来的时间是最短的。GPU 同样也能处理 AI,它的特点是带宽吞吐比较大,当用户需要的数据量比较高的时候,可以用 GPU 来做。通过 3 个 XPU 配合,就能合理的处理好复杂任务,以此得到最好的能效表现。
为了推动 AI PC 的发展,英特尔做了很多工作,目前英特尔计划到 2025 年推出超过 1 亿台的带有 AI 加速器,也就是 NPU 的电脑投放到市场上。目前,在英特尔生态系统里有大量的合作伙伴正在开发 AI 应用,或者是利用 AI 重塑已有的应用。根据英特尔提供的数据,目前英特尔已经有超过 100 家 ISV 合作伙伴,有超过 300 个拥有 AI 特性的应用。除了硬件之外,英特尔也 OpenVINO 这类统一的软件接口,通过 OpenVINO 将不同底层硬件架构封装成一个,甚至可以做到把 AI 负载能从 CPU 部署到 NPU 上,这也是一款广受业界欢迎业内广泛的框架。

酷睿 Ultra 提供了很好的 XPU 的算力,相比于其他硬件平台,英特尔酷睿 Ultra 带来了巨大的 AI 性能提升,无论是主流软件,还是本地文生图工具 Stable Diffusion 都有明显的优势。

英特尔酷睿 Ultra 所搭载的 NPU 特点是比较省电,处理也很高效。在 Zoom 视频会议的时候,通过把背景移除这些特效转移到 NPU 上,可以节省 38% 的功耗。UL Procyon AI Benchmark 也有 2.5 倍的功耗方面的节省,对于笔记本平台来讲,功耗节省还是很有意义的。

酷睿 Ultra 处理器配合 OpenVINO 可以支持多种数据类型,现阶段很多复杂模型跑到前端往往需要量化,FP32 很难跑到前端,所以现在能够去做量化,英特尔酷睿 Ultra 也可以很好的支持。比如英特尔酷睿 Ultra 对 8 位整形、16 位浮点等量化支持都很完善,无论是 CPU、GPU 还是 NPU,都可以很好的支持这些量化的数据类型。

目前市场上也出现了很多本地生成式 AI 模型,比如大语言模型 BERT、LLaMA2、GLM 2、GLM 3 等,再比如文生图 LCM 等,英特尔酷睿 Ultra 都很好的做到支持。通过英特尔酷睿 Ultra,在本地快速实现生成式 AI 的应用成为可能,无需笨重的独立显卡就可以在笔记本上实现,极大降低了 AI 使用的门槛。

目前英特尔已经与很多 ISV 合作,通过类似 OpenVINO 的工具,这些 ISV 所开发的应用可以有效利用英特尔最新的特性,比如集成显卡、NPU。另外,很多国内的大语言模型厂商合作,在合规前提下,也有与英特尔合作,并在酷睿 Ultra 平台上做了适配。在 AI 方面的合作,英特尔合作伙伴也在快速增长当中,预计到 2024 年上半年,这些 ISV 数量将增长到 100 家。


英特尔酷睿 Ultra 处理器产品参数
接下来,具体看一下英特尔酷睿 Ultra 处理器产品的特性和参数,全新的酷睿 Ultra 处理器产品,最高提供了 6+8+2 的处理器规格,英特尔硬件线程调度器也根据新的硬件调度模式进行了优化。
集成了全新的 Xe LPG 的引擎,在集显上有了一个大幅跃升。模块化设计的低功耗岛内置了 NPU,在内存规格上,支持 LPDDR5/5X-7467 与 DDR5-5600 规格,具备 1×8 PCle 5.0 高速通道以及 20 条等效于原来 CPU 直连的 PCIe 的通道。具有 4 个雷电 4 的接口,还有等效于原来芯片组的 8 条 PCle 通道,支持 Wi-Fi 6E 以及最新的 Wi-Fi 7 无线网卡。同时还内置了图象处理单元,以此提供摄像头高品质的解决方案。

英特尔一直为笔记本平台提供高速的连接方案,包括雷电 4、Wi-Fi 6E 以及最新的 Wi-Fi 7,通过英特尔 Killer 网络解决方案,基于新的人工智能连接优化方案,可以保证网络连接顺畅性以及稳定性。同时英特尔无线网卡包含蓝牙部分,支持新的 5.4 蓝牙规范,可以提供低功耗、高品质的音频连接。

英特尔酷睿 Ultra 处理器全家族型号与参数如下,本月发布会英特尔将率先推出英特尔酷睿 Ultra H 产品,其他型号产品将在 2024 年早些时间陆续发布。我们看到这次推出的英特尔酷睿 Ultra 处理器最高型号是酷睿 Ultra 7 165H,参数相比于前几代也更加详尽,其基础功耗为 28W,最大 Turbo 功耗为 65W 或 115W,并详细列出 P-Core 和 E-Core 的主频信息,P-Core 睿频为 5.0GHz,E-Core 睿频为 3.8GHz。

英特尔酷睿 Ultra 正式发布后到明年年初开始,将会和 35 家以上的 OEM 合作推出超过 230 款搭载 Meteor Lake 的计算机产品,并在通过 30 多家顶级零售商在全球发布。

英特尔 Evo 认证新标准
聊完处理器,我们再来看看英特尔 Evo 认证标准的进一步细化,英特尔 Evo 认证是英特尔建立的针对优秀移动笔记本认证标准,通过与业内全球顶级电脑制造商合作,带领 PC 生态系统推动平台创新,为用户提供更美好的笔记本体验。通过英特尔 Evo 平台严苛认证的笔记本电脑将附带英特尔 Evo 标识,方便消费者识别与选购。从某种程度上来说,英特尔 Evo 认证就是想方设法从各个角度去提升用户体验的体系。

此次英特尔酷睿 Ultra 处理器的发布,也意味着英特尔 Evo 认证标准的再一次迭代提升,进一步深化笔记本的体验细则。
具体来看,包括快速唤醒功能、基于性能和响应、平台相关的不同级别的技术、实际应用电池寿命、快速充电连接技术、外观创新、跨设备协同、可持续。

这里,英特尔 Evo 认证更加重视移动性能指标不受影响,具体来看,对于电池寿命,英特尔 Evo 目标是在 FHD 真实场景下电池续航超过 10 小时,另外风扇噪音也有新的指标,要求要够冷够安静。在快速响应时间上,英特尔 Evo 要求要小于 1.5 秒。再就是快速充电,要求充电半小时续航四小时。另外还要满足环保要求,需要达到 EPEAT 银级或通过 TCO 认证。
在智能连接方面,总共包括四部分。第一个是 VCX,用于提升摄像头的成像质量;在一个是 NPU,前面有详细提到;再就是 Wi-Fi 6E 智能连接和对 ICPS 的支持;最后一个就是基于微软的 MSE。


这次英特尔酷睿 Ultra 同样支持多设备协同技术 Intel Unison,这一次 Intel Unison 扩展到安卓、iOS 全平台,并支持屏幕扩展以及在笔记本电脑和移动设备上进行文件和图像共享。未来还将增加通用控制功能,这项功能可以通过鼠标跨设备控制不同设备。Swift connect 是快速连接,也是轻便连接技术,可以将设备快速接入

对于外设,英特尔也有专门的认证体系来让合作伙伴满足 Evo 的要求。比如说新的外形设计,还有雷电拓展坞、显示屏、存储器、键鼠耳机、AP 设备等都有专门的符合 Evo 认证的产品。

总结
这一次英特尔酷睿 Ultra 处理器的发布也让我们看到 AI PC 正加速走进我们日常的工作和生活。全新的处理器形态,通过 CPU、GPU、NPU 三层 AI 算力网络,Meteor Lake 将客户端处理器的 AI 加速能力推到了新高度,在这样的算力网络支持下,本地大语言模型、AIGC 相关话题可以跳脱云上算力,使得 AI 在边缘计算领域进一步深化。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






